よくある文字形式のcaptcha画像の読み取りを「OpenCV」と「Tesseract OCR」で試してみました。
今回扱う画像はこちらです。

試したい場合はダウンロードしてプログラムと同じディレクトリに置いてください。
事前準備
windowsの場合は事前にTesseractOCRの exeファイルをインストールする必要があります。 初回はJupyterNotebook上で下記コードを実行してライブラリをインストールしておきます。
!pip install opencv-python pyocr tesseract正常にインストールできていれば下記コードで画像が表示されるはずです。
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('captcha.png')
plt.title('orginal')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
2値化
文字認識しやすいように白黒のみの画像に変換します。
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.title('img_gray')
plt.imshow(cv2.cvtColor(img_gray, cv2.COLOR_BGR2RGB))
plt.show()
ret, img_binary = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_TRIANGLE)
plt.title('img_binary THRESH_TRIANGLE')
plt.imshow(cv2.cvtColor(img_binary, cv2.COLOR_BGR2RGB))
plt.show()
ret, img_binary = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
plt.title('img_binary THRESH_OTSU')
plt.imshow(cv2.cvtColor(img_binary, cv2.COLOR_BGR2RGB))
plt.show()
大津の2値化のほうがよさげです(# 名前もカッコイイ)
ゴミ除去
ハフ変換を用いて画像内の線分を検出し、検出した線分を黒く塗ることで線を除去します。
小さいゴミは後で除去できるので「細い線」で「砕き」ます。
import numpy as np
output =img_binary.copy()
color_output = cv2.cvtColor(output, cv2.COLOR_GRAY2BGR)
for a in range(6) :
lines = cv2.HoughLinesP(output, rho=0.6, theta=np.pi/360, threshold=10, minLineLength=21-a, maxLineGap=1.0)
if lines is not None :
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(output, (x1, y1), (x2, y2), (0, 0, 0), 1)
cv2.line(color_output, (x1, y1), (x2, y2), (0, 255, 0), 1)
break
plt.title('color_output')
plt.imshow(cv2.cvtColor(color_output, cv2.COLOR_BGR2RGB))
plt.show()
plt.title('removed_line')
plt.imshow(cv2.cvtColor(output, cv2.COLOR_BGR2RGB))
plt.show()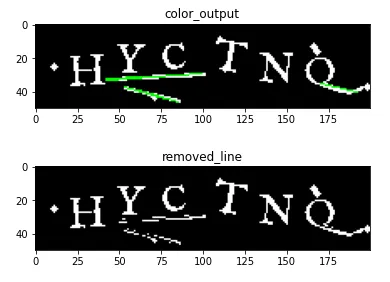
エッジ検出を行い、小さい領域は除去します。
その後、検出したエッジにマスクをかけ、その領域以外を除去します。
# エッジ検出
contours, hierarchy = cv2.findContours(output, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# ちいさい領域削除 the region of interest (ROI)
roi = [obj for obj in contours if not cv2.contourArea(obj)<=12]
# 検出枠表示用に入力画像をカラーデータに変換する
output_color = cv2.cvtColor(output, cv2.COLOR_GRAY2BGR)
for contour in roi:
(x, y, w, h) = cv2.boundingRect(contour)
region = output_color[y:y+h, x:x+w]
# 最小外接矩形を求める
rect = cv2.minAreaRect(contour)
# 矩形の4つの角の座標を求める
box = cv2.boxPoints(rect)
box = np.int0(box)
# 矩形を描画する
cv2.drawContours(output_color, [box], 0, (0, 255, 0), 1)
plt.title(f'roi length={len(roi)}')
plt.imshow(cv2.cvtColor(output_color, cv2.COLOR_BGR2RGB))
plt.show()
# 興味ある部分のみ白マスク
mask = np.zeros(output.shape[:2], dtype=np.uint8)
cv2.fillPoly(mask, roi, 255)
# 白マスクしたとこだけ残す
output = cv2.bitwise_and(output, output, mask=mask)
plt.title('result')
plt.imshow(cv2.cvtColor(output, cv2.COLOR_BGR2RGB))
plt.show()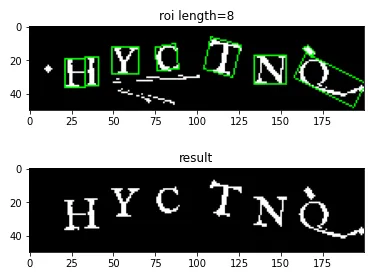
OCRでテキスト読み取り
テキストを読み取るための下準備ができましたのでOCRで読み取ってみます。
事前に検出する文字が決まっている場合はwhitelistを指定すると検出しやすいです。
OCRインストール先のconfigフォルダにalphabetというファイル名で保存しておきます。
tessedit_char_whitelist ABCDEFGHIJKLMNOPQRSTUVWXYZ「tesseract_layout」は「10」の「画像を1つの文字として扱う」と指定しておきます。
import pyocr
from PIL import Image
# ndarrayをpillowのImageに変換
pil_img = Image.fromarray(cv2.cvtColor(output, cv2.COLOR_BGR2RGB))
# OCRエンジンを取得(事前にOSでインストールしておく必要がある)
pyocr.tesseract.TESSERACT_CMD = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
engines = pyocr.get_available_tools()
engine = engines[0]
builder = pyocr.builders.TextBuilder(tesseract_layout=10)
builder.tesseract_configs.append("alphabet")
# 画像の文字を読み込む
text = engine.image_to_string(pil_img, lang="eng", builder=builder)
print(f'"{text}"')
一応傾き補正もしてみましたが、あまり結果が変わらないので取り入れませんでした。
adjust_skew = output.copy()
contours, hierarchy = cv2.findContours(adjust_skew, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 検出枠表示用に入力画像をカラーデータに変換する
output_color = cv2.cvtColor(output, cv2.COLOR_GRAY2BGR)
for contour in contours:
(x, y, w, h) = cv2.boundingRect(contour)
# ある程度横長のものは無視する
if w >= 35 : continue
region = adjust_skew[y:y+h, x:x+w]
# 最小外接矩形を求める
rect = cv2.minAreaRect(contour)
# 矩形の4つの角の座標を求める
box = cv2.boxPoints(rect)
box = np.int0(box)
# 矩形を描画する
cv2.drawContours(output_color, [box], 0, (0, 255, 0), 1)
# 矩形の傾きを計算する
angle = rect[2]
if angle > 45:
angle = -(angle - 90)
else :
angle = -angle
center = (w / 2, h / 2)
# 回転のための変換行列の生成
# cv2.getRotationMatrix2D(入力画像の回転中心, 回転角度 単位は度 - 正の値:反時計回り, 等方性スケーリング係数 - 拡大縮小の倍率)
M = cv2.getRotationMatrix2D(center, -angle, 1.0)
# v2.warpAffine(元の画像, cv2.getRotationMatrix2Dで生成した2*3の変換行列, 出力する画像サイズ(縦の高さ, 横の幅))
rotated_region = cv2.warpAffine(region, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
adjust_skew[y:y+h, x:x+w] = rotated_region
plt.title('before')
plt.imshow(cv2.cvtColor(output_color, cv2.COLOR_BGR2RGB))
plt.show()
contours, hierarchy = cv2.findContours(adjust_skew, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 検出枠表示用に入力画像をカラーデータに変換する
output_color = cv2.cvtColor(adjust_skew, cv2.COLOR_GRAY2BGR)
for contour in contours:
(x, y, w, h) = cv2.boundingRect(contour)
region = output_color[y:y+h, x:x+w]
rect = cv2.minAreaRect(contour)
box = cv2.boxPoints(rect)
box = np.int0(box)
cv2.drawContours(output_color, [box], 0, (0, 255, 0), 1)
plt.title('after')
plt.imshow(cv2.cvtColor(output_color, cv2.COLOR_BGR2RGB))
plt.show()
おわりに
今回は比較的簡単な文字captcha画像を扱いましたが、ノイズが文字にかかった場合などは誤認識が多発します。
OCRの部分を機械学習データを自作することで、より精度を上げることができると思います。